
Navegação agêntica é o uso autônomo da web por agentes de IA que leem, navegam e executam tarefas em sites, exigindo páginas com estrutura e ações legíveis por máquina.
A web foi construída para olhos humanos. Cada botão, formulário e menu pressupõe alguém que lê, interpreta e clica. Esse pressuposto deixou de valer. Agentes de IA hoje navegam sites, preenchem formulários e concluem fluxos de várias etapas sem intervenção humana, e fazem isso interpretando a página de maneira distinta da nossa.
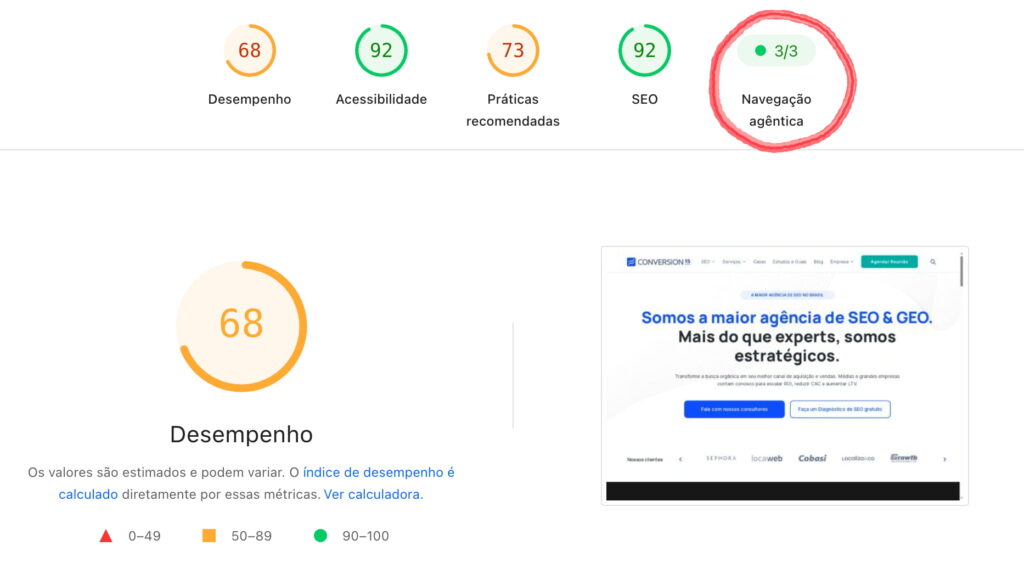
O movimento ganhou peso institucional em maio de 2026, quando o Google adicionou uma categoria experimental chamada “Agentic Browsing” ao Lighthouse 13.3, parte das ferramentas de desenvolvedor do Chrome. Semanas depois, a categoria foi herdada pelo PageSpeed Insights. Pela primeira vez, há um conjunto de sinais padronizados que mede quão preparado um site está para ser operado por máquinas.
Para quem opera sites no Brasil, onde a maioria roda sobre WordPress, page builders visuais e formulários de terceiros, o desafio não está no conceito, e sim na execução. As próximas seções traçam o método para auditar, corrigir e validar a prontidão agêntica do seu site, separando responsabilidade de plugin, tema e conteúdo.
O que muda quando o usuário é um agente, não uma pessoa
Um agente de IA não enxerga sua página como um navegador humano. Ele consome uma representação estruturada: a árvore de acessibilidade, o HTML renderizado e, quando capta a tela, capturas de imagem que dependem da posição visual dos elementos. O que para nós é óbvio, para o agente pode ser invisível.
Considere um botão de ícone sem texto. Um humano reconhece a lupa como “buscar”. O agente lê a árvore de acessibilidade e encontra um elemento sem nome programático, ou seja, uma ação que ele não sabe nomear nem acionar. O mesmo vale para um link de imagem com alt="": visualmente perfeito, semanticamente mudo.
Essa diferença redefine prioridades de engenharia. Acessibilidade deixa de ser apenas conformidade com diretrizes para pessoas com deficiência e passa a ser pré-requisito de operabilidade por máquina. A boa notícia é que sites com acessibilidade sólida já partem com vantagem, porque os agentes reaproveitam exatamente os mesmos sinais.
Há ainda uma camada de proatividade. Em vez de deixar o agente adivinhar como interagir, o site pode declarar suas próprias ferramentas, dizendo de forma explícita “aqui você busca produtos”, “aqui você adiciona ao carrinho”. É a diferença entre esperar que o agente decifre a interface e oferecer a ele uma porta de entrada estruturada.
A categoria Agentic Browsing do Lighthouse, em detalhe
A categoria entrou na configuração padrão do Lighthouse 13.3 em maio de 2026 e permanece marcada como experimental. Convém deixar claro o que ela é e o que não é: trata-se de um instrumento de medição, não de um fator de ranqueamento. Sites comuns, sem recursos voltados a IA, não sofrem penalidade.
A pontuação também foge ao modelo conhecido. Em vez da nota ponderada de 0 a 100, a categoria mostra um score fracionário, ou seja, quantos checks de prontidão o site passa, acompanhado de status pass/fail por auditoria. A escolha é deliberada: como os padrões da web agêntica ainda estão em formação, o objetivo é coletar dados e sinalizar ações concretas, não emitir um veredito definitivo.
Os quatro grupos de sinais
A categoria combina quatro famílias de verificações, cada uma endereçando uma forma distinta de o agente interagir com a página:
| Grupo de sinais | O que mede | Falhas comuns |
|---|---|---|
| Acessibilidade para agentes | Nome programático de links, botões e inputs; integridade de papéis e relações na árvore | aria-label ausente, inputs sem label, alt="" em links de imagem |
| Estabilidade de layout (CLS) | Constância da posição visual dos elementos | Banners, embeds e formulários de terceiros que carregam tarde |
| llms.txt | Presença de um resumo legível por máquina na raiz do domínio | Arquivo ausente, sem H1, sem links ou abaixo do tamanho mínimo |
| WebMCP | Ferramentas registradas e validade de schema | Schema inválido, ferramentas não registradas |
A camada de acessibilidade reaproveita auditorias que o Lighthouse já realizava, filtrando o subconjunto crítico para interação por máquina. A estabilidade de layout usa a métrica CLS porque o agente, ao depender de capturas de tela, precisa que os elementos permaneçam onde estavam. No ambiente mobile, onde o espaço é menor e os reflows são mais frequentes, o problema costuma aparecer com mais clareza.
O caso particular do llms.txt
O llms.txt é um arquivo Markdown colocado na raiz do domínio, com um resumo do site pensado para consumo por modelos de linguagem. O Lighthouse valida sua presença, se responde com HTTP 200, se contém um H1, se atinge um comprimento mínimo e se traz links.
Aqui mora um mal-entendido recorrente. Segundo o Google, com John Mueller à frente da comunicação, o llms.txt não é necessário para a Busca. Sua função é outra: descoberta e funcionalidade por agentes. Implementá-lo não melhora seu ranqueamento orgânico, mas amplia a chance de um agente compreender e operar o site.
WebMCP: do conceito à porta de entrada estruturada
Entre os quatro sinais, o WebMCP é o mais novo e o que exige mais decisão de engenharia. Trata-se de um protocolo que permite ao site expor ferramentas diretamente ao agente que roda no navegador. Em vez de o agente inferir ações observando a interface, o site as declara. O recurso chegou como origin trial a partir do Chrome 149, o que permite testá-lo com usuários reais em produção.
O protocolo oferece duas APIs. A imperativa usa JavaScript: você registra uma ferramenta com navigator.modelContext.registerTool, define um schema de entrada e fornece um handler que executa a lógica já existente no seu código. A declarativa atua sobre formulários que já existem na página, por meio de atributos HTML como toolname, tooldescription e toolparamdescription no elemento <form>.
Um exemplo declarativo, aplicado a um formulário de busca, ilustra a simplicidade da abordagem:
<form action="/busca" method="get"
toolname="buscar_produtos"
tooldescription="Busca produtos no catálogo por palavra-chave">
<input type="text" name="q"
toolparamdescription="Termo de busca, ex.: tênis de corrida">
<button type="submit">Buscar</button>
</form>
O WebMCP é parente próximo do Model Context Protocol, padrão que conecta modelos a fontes de dados e ferramentas. A diferença é o ambiente: enquanto o MCP opera no lado do servidor ou em integrações de back-end, o WebMCP vive no navegador, herdando a sessão de quem navega.
WebMCP seguro versus capacidade falsa
A facilidade de declarar ferramentas cria um risco de mão dupla. Expor capacidades atrai agentes, mas expor capacidades de forma irresponsável abre brechas de segurança e mina a confiança. A diretriz prática é começar pelo mínimo e ampliar com cautela.
A recomendação inicial é manter tudo read-only, isto é, ferramentas que apenas leem e retornam dados, sem modificar estado. Ações sensíveis, como concluir uma compra ou apagar registros, exigem humano no circuito: o agente prepara, a pessoa confirma. Some-se a isso o isolamento de origem, para que um script não acesse ferramentas de outro contexto, e atenção redobrada com scripts de terceiros que possam sobrescrever ou sequestrar ferramentas registradas.
Existe, porém, uma fronteira que jamais deve ser cruzada: publicar capacidade falsa. Anunciar um MCP Server Card sem servidor por trás, ou metadados fictícios de OAuth, A2A ou commerce, é convidar o agente a tentar uma ação que não existe. O resultado é falha em cadeia, perda de confiança e, em ambientes mais exigentes, risco de o site ser marcado como não confiável. Declare apenas o que de fato funciona.
A metodologia para o ambiente brasileiro: WordPress, builders e terceiros
A cobertura internacional, de DebugBear a Search Engine Land, explica bem o conceito. O que ela deixa de fora é o método para o ambiente onde a web brasileira de fato vive. Aqui, a maior parte dos sites roda sobre WordPress e page builders visuais, e os formulários muitas vezes vêm de plataformas de terceiros. É nesse vão entre conceito e execução que os problemas se concentram.
A primeira regra é separar responsabilidades. Em um site WordPress, três camadas distintas determinam a prontidão agêntica, e cada uma exige tratamento próprio:
- Plugin: implementa as capacidades agênticas, como WebMCP, llms.txt e endpoints estruturados. É a camada onde a maior parte da prontidão é programada.
- Tema: define o HTML renderizado, a estrutura de headings e a marcação de elementos interativos. É onde nascem os problemas de árvore de acessibilidade.
- Conteúdo: o que o editor publica, com seus embeds, banners e formulários incorporados. É a fonte mais frequente de instabilidade de layout.
A segunda regra decorre da primeira. Em WordPress e em builders visuais, o HTML final quase nunca corresponde ao que se vê no editor. O page builder injeta wrappers, scripts e estilos que só aparecem na renderização. Por isso, teste sempre o HTML renderizado, nunca o que o editor mostra. Um botão que parece ter rótulo no editor pode chegar mudo ao navegador.
A terceira regra trata do CLS, o vilão silencioso. Banners de marketing, embeds de vídeo e formulários de terceiros costumam carregar de forma assíncrona e empurrar o conteúdo para baixo depois do primeiro paint. Para o agente, que depende da posição visual, esse deslocamento quebra a interação. Reservar espaço com dimensões explícitas para imagens e iframes, e definir altura mínima para áreas que recebem conteúdo tardio, resolve a maioria dos casos.
Triagem rápida das falhas mais comuns
Antes de partir para auditorias formais, vale fazer uma triagem manual das falhas que mais reprovam sites brasileiros:
- Link de imagem com
alt="", que vira âncora sem nome na árvore de acessibilidade. - Botões de ícone sem
aria-label, comuns em menus, buscas e ações de carrinho. - Inputs de formulário sem label associado, sobretudo em formulários de terceiros.
- CLS provocado por banners, embeds e widgets que carregam tarde.
Esses quatro itens respondem pela maioria das reprovações. Corrigi-los costuma elevar o score fracionário de forma imediata, sem necessidade de implementar WebMCP de saída.
Como auditar: do Lighthouse aos scanners de prontidão
A auditoria começa no próprio Lighthouse. Pela CLI, o comando abaixo gera um relatório focado na categoria, em modo mobile, que tende a expor mais problemas de layout:
lighthouse https://seusite.com.br \
--only-categories=agentic-browsing \
--form-factor=mobile \
--output=html \
--output-path=./relatorio-agentic.html
O relatório aponta o score fracionário e o status de cada auditoria, mas não substitui uma visão de prontidão mais ampla, que cubra descoberta, políticas de bots e protocolos. Para isso, dois scanners gratuitos complementam bem o diagnóstico e reforçam a base de evidências.
O Agent Crawl, ferramenta gratuita desenvolvida pela Conversion, mede a prontidão agêntica em cinco categorias: descoberta (robots.txt e sitemaps), conteúdo (Markdown extraível e dados estruturados), bots (políticas de acesso), protocolos (MCP, .well-known e API Catalog) e ação. A saída é um checklist priorizado com evidências, o que facilita decidir o que corrigir primeiro.
Na mesma linha, o scanner Is It Agent Ready, da Cloudflare, também avalia cinco frentes: descoberta (robots.txt, sitemaps, headers e DNS), acessibilidade de conteúdo (negociação de Markdown), controle de bots (Content Signals e Web Bot Auth), descoberta de protocolos (MCP, Agent Skills, WebMCP, OAuth e API catalogs) e comércio. Rodar os dois lado a lado revela divergências úteis e cobre ângulos que o Lighthouse não alcança.
A combinação forma um trio de auditoria: o Lighthouse para os quatro sinais oficiais, o Agent Crawl para a visão de prontidão por evidências e o Is It Agent Ready para a checagem cruzada de protocolos e bots. Esse cruzamento é parte do trabalho de rastreamento por IA que sustenta uma estratégia de GEO consistente.
Como implementar WebMCP com segurança em WordPress
A implementação madura começa pequena e cresce por etapas. O primeiro release expõe só ferramentas read-only de leitura de conteúdo público, valida tudo no Lighthouse e nos scanners, e só depois avança para ações que escrevem, sempre com confirmação humana. Concentre o registro de ferramentas em um único ponto controlado, porque cache, CDN e plugins de formulário alteram o HTML final que o agente lê. Para a base conceitual, vale a leitura do guia de WebMCP: o que é e como implementar e do artigo sobre Model Context Protocol (MCP), que cobre o lado servidor do protocolo.
O arquivo de contexto se soma a esse esforço. Um llms.txt claro dá ao agente um mapa do site antes da primeira chamada de ferramenta, reduzindo tentativa e erro. A combinação de descoberta enxuta e ferramentas read-only entrega prontidão real sem abrir risco, que é exatamente o equilíbrio que a categoria do Lighthouse premia.
Case Conversion: o plugin Conversion Agent Discovery
A Conversion, pioneira em Generative Engine Optimization no Brasil, mantém um plugin open source que materializa boa parte dessa metodologia em WordPress: o Conversion Agent Discovery, disponível no repositório oficial do WordPress.org.
O plugin implementa WebMCP no lado do navegador em modo read-only, com aliases wp_*, schemas que usam additionalProperties:false, além de readOnlyHint e untrustedContentHint. Junto disso, ele gera o llms.txt, expõe /.well-known/api-catalog, oferece Agent Skills, faz negociação de Markdown via cabeçalho Accept: text/markdown e disponibiliza endpoints REST somente leitura com rate limit. Os formulários declarativos ficam por opt-in, ativados de forma deliberada pelo administrador.
O ponto mais relevante, à luz da seção sobre capacidade falsa, é o que o plugin não faz: ele não publica metadata fictícia de OAuth, MCP Server Card, A2A ou commerce. Declara apenas o que existe. Some-se a isso uma orientação prática de prontidão Agentic Browsing, alinhada aos checks de PageSpeed e Lighthouse, e o plugin se torna um ponto de partida coerente com tudo o que descrevemos. Vale destacar que ele é referência, não substituto, do trabalho de auditoria e correção das camadas de tema e conteúdo.
Onde a navegação agêntica se conecta com GEO e dados estruturados
Preparar o site para agentes não é uma iniciativa isolada. É parte de uma disciplina maior, que conecta SEO tradicional, otimização para motores generativos e a marcação semântica do conteúdo. Os mesmos sinais que ajudam um agente a operar a página ajudam um modelo a compreendê-la e citá-la.
A relação com a Generative Engine Optimization (GEO) é direta: agentes e motores generativos compartilham a necessidade de conteúdo legível por máquina, estrutura clara e ações declaradas. Quem trata esses temas de forma integrada constrói uma vantagem difícil de copiar, especialmente em um mercado ainda no início da curva de adoção.
Os dados estruturados cumprem papel complementar. Schema.org descreve o significado do conteúdo, enquanto WebMCP descreve as ações disponíveis. Um informa “isto é um produto, com este preço”; o outro informa “aqui você compra este produto”. Juntos, dão ao agente um mapa completo de leitura e operação. Esse encaixe é o cerne de uma estratégia madura de SEO e inteligência artificial.
O timing para o mercado brasileiro
O cenário brasileiro favorece quem se move agora. Segundo o DataReportal, o relatório Digital 2026 aponta cerca de 185 milhões de usuários de internet no país, base ampla o suficiente para que a adoção de agentes ganhe escala rápida assim que os recursos se popularizarem.
Do lado das empresas, os dados do Cetic.br mostram aceleração. O uso de inteligência artificial por empresas brasileiras subiu de 13% em 2024 para 17% em 2025, com salto mais expressivo entre grandes empresas, de 38% para 50% no mesmo período. A geração de linguagem natural foi a aplicação que mais cresceu, de 20% para 30%, o que indica familiaridade crescente com a tecnologia que sustenta os agentes.
A leitura estratégica é simples. A prontidão agêntica ainda não é fator de ranqueamento e os padrões seguem em formação, o que significa baixa concorrência e custo de adoção reduzido. Sair na frente custa pouco e constrói posição. Esperar a consolidação do padrão significa competir quando todos já tiverem se mexido.
Perguntas frequentes sobre navegação agêntica
A categoria Agentic Browsing do Lighthouse afeta meu ranqueamento no Google?
Não. A categoria é experimental e serve para medição e sinalização de melhorias, não como fator de ranqueamento. Sites sem recursos voltados a IA não sofrem penalidade. Trata-se de um diagnóstico de prontidão, não de uma nota de busca.
Preciso implementar llms.txt para aparecer no Google?
Não. O próprio Google afirma que o llms.txt não é necessário para a Busca. Sua função é descoberta e funcionalidade por agentes de IA. Implementá-lo amplia a chance de um agente compreender e operar o site, mas não altera o ranqueamento orgânico.
Qual a diferença entre WebMCP e MCP?
Ambos expõem ferramentas a modelos de IA, mas em ambientes distintos. O MCP opera no servidor ou em integrações de back-end, conectando modelos a fontes de dados. O WebMCP roda no navegador, permitindo que o próprio site declare ferramentas ao agente que navega na página.
Como começar a implementar WebMCP com segurança?
Comece read-only, com ferramentas que apenas leem e retornam dados. Reserve ações sensíveis para confirmação humana, aplique isolamento de origem e atente para scripts de terceiros que possam sobrescrever ferramentas. Nunca declare capacidade que o site não tem de fato.
Quais são as falhas mais comuns em sites WordPress?
As mais frequentes são links de imagem com alt="", botões de ícone sem aria-label, inputs sem label e CLS causado por banners, embeds e formulários de terceiros que carregam tarde. Como o HTML final difere do editor, é essencial testar a versão renderizada da página.
Quais ferramentas gratuitas avaliam a prontidão agêntica?
Além do Lighthouse, dois scanners gratuitos ajudam: o Agent Crawl, da Conversion, com checklist priorizado por evidências em cinco categorias, e o Is It Agent Ready, da Cloudflare, que cobre descoberta, controle de bots, protocolos e comércio. Rodar os dois em conjunto cobre ângulos complementares.
Conclusão: por onde começar
A navegação agêntica deixou de ser tese e virou medição padronizada dentro de ferramentas que você já usa. O caminho para se preparar não exige reescrever o site, e sim seguir uma sequência clara de passos acionáveis:
- Audite com a categoria Agentic Browsing do Lighthouse e cruze o resultado com Agent Crawl e Is It Agent Ready.
- Corrija primeiro a acessibilidade: nomes programáticos em botões, links e inputs. É o ganho mais rápido e reaproveita trabalho de acessibilidade que talvez já exista.
- Estabilize o layout: reserve espaço para imagens, iframes, banners e embeds de terceiros para conter o CLS.
- Publique um llms.txt válido na raiz, com H1, comprimento adequado e links.
- Avalie o WebMCP começando read-only, declarando apenas capacidades reais e mantendo humano no circuito para ações sensíveis.
- Teste sempre o HTML renderizado, separando o que cabe ao plugin, ao tema e ao conteúdo.
Em WordPress, o plugin Conversion Agent Discovery encurta boa parte desse caminho, desde que acompanhado da correção manual das camadas de tema e conteúdo. O mercado brasileiro ainda está no começo da curva. Quem implementar agora paga custo baixo e constrói posição antes que a prontidão agêntica deixe de ser diferencial e passe a ser obrigação.

